この記事は2002年11月時点のD言語に関するレポートです。
かなり古くて、1.0 以降のDについて調べる資料としては全く役に立ちません。
歴史的資料としてのみ残してあります。
最新のD言語に関して知りたい方は、ここ D Memo の全面改訂版
わかったつもりになるD言語
をどうぞ。
D Memo
プログラミング言語Cからは、わりと純粋なオブジェクト指向を入れた「Objective-C」
や色々なパラダイムを突っ込みまくった「C++」、それを整頓し直したつもりになって、
C++より少しobjectiveになった「Java」や「C#」といったメジャーな言語が、
次々と派生してきました。更に少しマイナーなところでは、ML風味を加えて型安全を目指す
Cyclone や、
コンパイル時の MetaObject-protocol を C++ に加えた
OpenC++、Rule
という概念をサポートする R++ など。Objective-C++ という菱形継承な言語もあるそうです。
並べているだけで楽しいのですが、それは脇に置いておいて。今回はそんな
C系統の言語の一つ、D言語( D Programming Language )について調べてみることにしました。
調べながら書いているので、間違いも多いかもしれません。指摘大歓迎です。
- introduction
- install
- hello, world
- d-way to read/write
- function
- class
- module
- * attribute
- * constructor
- * GC/auto
- inheritance
- 休憩
- type
- operator overload
- template
- exception
- primitives , array
- * debug, version
- * contract, invariant, unittest
- phobos
- other libraries
introduction (2003/01/05)
Dとは、1999年以来 Walter Bright
氏によって開発されている比較的新しい言語で、作者氏によれば、C や C++
の後継として位置づけられています。C に Class や Template、
例外処理やRTTI、Contract と言った拡張がほどこされ、プリプロセッサや、
C++の多重継承と言った部分は抜いた言語となっています。メモリ管理は
Garbage Collector で行いますが、C++のデストラクタ風の、
スコープアウト時のリソース破棄もサポートしているようです。詳細は追々…
ですが、現在はalpha版なので、言語仕様等今後も変化する可能性があります。
ご了承を。
処理系は現在の所、オフィシャルには
Win32用コンパイラ
のみが提供されています。リンカはC用のものが使えるそうです(同ページから、
リンカもダウンロードできます。)
また、OpenD.org にて、
Linuxへの移植やGUIライブラリが公開されています。
以下では、Windows用の D 0.50 (Nov 20, 2002) を使って話を進めていきます。
install (2003/01/05)
- ダウンロードページ
から、'D Compiler' と 'linker and utilities' を取得。
- 両方を解凍。
- 後者を解凍してできるdmフォルダを、前者のdmフォルダに上書き。
- 解凍して出来た dmd\bin フォルダへパスを通す。(WinNT系であれば、
コントロールパネル→システムのプロパティ→詳細設定→環境変数→PATHに追加。
Win9x系であれば、システムドライブのルートのAUTOEXEC.BATのPATH=を変更。)
で OK。後は、ソースを書いて、そのソースのあるフォルダでコマンドプロンプトから
dmd hogehoge.d
と打てばコンパイルできます。
hello, world. (2003/01/05)
まずはこれを書かないと始まらないのです。Hello, World. と出力するプログラム。
import c.stdio;
int main( char[][] arg )
{
printf( "Hello, World.\n" );
return 0;
}
>> 実行結果
Hello, World.
import で、他のモジュールを読み込み- 実行は、
int main( char[][] ) 関数から始まる。
- 基本的な文法はC言語そのまんま
d-way to read/write (2003/01/06)
上の例では、c.stdio とあったことからもわかるように、
C言語のprintf関数をそのまま呼び出していました。ここでは、
D独自の入出力機構を使ってみます。c.stdio ではなく、stream
モジュールを使います。
import stream;
int main( char[][] arg )
{
stdout.writeString( "Are you happy ? " );
char[] str = stdin.readLine();
if( str[0]=="y" || str[0]=="Y" )
stdout.writeLine( "That's good!" );
else
stdout.writeLine( "Oh, that's bad..." );
return 0;
}
>> 実行結果
Are you happy ? No
Oh, that's bad...
>> 実行結果2
Are you happy ?
Error: ArrayBoundsError test.d(9)
stdout.writeLine で、一行出力stdin.readLine で、一行入力- 配列の外にアクセスするとArrayBoundsErrorというのが出て強制終了
- if文もCと同じ
import stream;
import string;
int main( char[][] arg )
{
stdout.writeLine( 'printing...' );
for( int i=0; i<5; ++i )
{
for( int j=0; j<5; ++j )
{
stdout.write( digits[i] );
stdout.write( digits[j] );
stdout.writeString( ' ' );
}
stdout.writeString( "\n" );
}
return 0;
}
>> 実行結果
printing...
00 01 02 03 04
10 11 12 13 14
20 21 22 23 24
30 31 32 33 34
40 41 42 43 44
- [文字一文字]をダイレクトに表現する手段は無い。全て[文字列]
""でも''でも複数文字をくくって、
文字列にできる。後者の中では \ によるエスケープシーケンスが効かない。- stdout.write はcharを取ったりchar[]を取ったりintを取ったり色々書ける関数。
intを取ると、その整数値をフォーマットせずそのまま書くので注意。
- for文もCと同じ
import stream;
int main( char[][] arg )
{
stdout.write( "x" );
return 0;
}
>> コンパイル結果
test.d(5): function write overloads void(char x) and void(char[]) both
match argument list for write
- 一文字の文字列リテラルは、暗黙の内にcharへ変換されうるらしい。
- write(char)とwrite(char[])が曖昧と言われて困る
import stream;
int main( char[][] arg )
{
if( arg.length < 2 )
{
stdout.writeLine( 'Bye' );
return -1;
}
switch( arg[1] )
{
case 'this':
stdout.writeLine( 'kore' );
break;
case 'is':
stdout.writeLine( 'desu' );
break;
case 'a':
stdout.writeLine( 'hitotsu' );
break;
case 'pen':
stdout.writeLine( 'pen' );
break;
}
return 0;
}
>> 実行結果
< sample test
kore
< sample
Bye
< sample hoge
Error: Switch Default test.d(11)
- switch文もだいたいCと同じ
- fall through するのでbreakは必要
- 整数だけでなく、文字列もcaseに取れる。(他はダメ)
- defaultがないときに当てはまるcaseが無いとエラーになって大変。
functions (2002/01/08)
関数、の書き方。
import stream;
double square( double x )
{
return x * x;
}
int main( char[][] arg )
{
double y = square( 3.0 );
stdout.writeLine( toString(y) );
return 0;
}
>> 実行結果
9
上の例のsquareは、double型のパラメータを一つ受け取って、
それの自乗を計算して返す関数となっています。ご覧の通り、
例によって、C と全く同じに書けます。
import stream;
int main( char[][] arg )
{
double y = square( 3.0 );
stdout.writeLine( toString(y) );
return 0;
}
double square( double x )
{
return x * x;
}
mainの下に書くこともできます。C言語でこうするためには、
「プロトタイプ宣言」が必要になりますが、Dの場合は平気です。
もちろん逆に書いてもちゃんと型のチェックも行われます。
Java使いの方にとっては当たり前の動作だと思います。
C++使いの人も、classの中では関数の定義順序は自由、
なことを思い出していただければ、それを一般に拡張したと考えれば良さそう。
多重定義
import stream;
int main( char[][] arg )
{
stdout.printf( "%d\n", add(1, 2) );
stdout.printf( "%d\n", add(1, 2, 3) );
stdout.printf( "%f\n", add(1.0, 0.5) );
stdout.printf( "%f\n", add(1.0, 0.5, 0.25) );
return 0;
}
int add( int a, int b )
{
return a + b;
}
int add( int a, int b, int c )
{
return a + b + c;
}
double add( double a, double b )
{
return a + b;
}
double add( double a, double b, double c )
{
return a + b + c;
}
>> 実行結果
3
6
1.500000
1.750000
関数オーバーロード。同じ名前の関数であっても、
与えた引数の個数や引数の型によって自動的に適切な物を選んで呼び出します。
ただし、例えば add( 1, 2.0 ) のような曖昧な引数を与えると、
int,intなのかdouble,doubleなのかがわからなくてコンパイルエラーになります。
めっちゃ余談ですが、
上に乗ってしまって別の定義を見えなくするのが「オーバーライド」
で、沢山同じ名前の関数を定義しまくる方が「オーバーロード」、
と覚えると混同しにくいです。脱線。
入出力指定
import stream;
void f( out int x )
{
x = 100;
}
int main( char[][] arg )
{
int t;
f( t );
stdout.writeLine( toString(t) );
return 0;
}
>> 実行結果
100
out と修飾された引数を関数の中で書き換えると、
呼び出し元の変数の値が書き変わります。他に in と
inout の3種類があって、何もつけないとin扱いだそうです。
もう少し細かく見てみましょうか。
import stream;
void f( in int x ) { stdout.printf( " %d", x ); }
void g( out int x ) { stdout.printf( " %d", x ); }
void h( inout int x ) { stdout.printf( " %d", x ); }
void ff( in int x ) { x=100; }
void gg( out int x ) { x=100; }
void hh( inout int x ) { x=100; }
int main( char[][] arg )
{
int x;
x = 20; stdout.printf("%d",x); f(x); stdout.printf(" %d\n",x);
x = 20; stdout.printf("%d",x); g(x); stdout.printf(" %d\n",x);
x = 20; stdout.printf("%d",x); h(x); stdout.printf(" %d\n",x);
x = 20; stdout.printf("%d",x); ff(x); stdout.printf(" %d\n",x);
x = 20; stdout.printf("%d",x); gg(x); stdout.printf(" %d\n",x);
x = 20; stdout.printf("%d",x); hh(x); stdout.printf(" %d\n",x);
return 0;
}
>> 実行結果
20 20 20
20 20 20 // 20 0 0 になって欲しかった…
20 20 20
20 20
20 100
20 100
うむ。ドキュメントと書いてあることが違う。。。out な引数は
呼び出しの時に初期化(intなら0になる)されるはずなのですが、
そうなっていないようです。inoutと区別している以上、
初期化されるのが正しい動作でしょうから、コンパイラの問題かなぁ。
調べてみます。
class (2003/01/14)
前回の補足~。
質問してみたところ、outの結果はやっぱりバグだそうです。
というわけで、上の例では 20 0 0 になるのが正しいらしい。結局、
in ならその引数変数に値を代入しても呼び出し元は変わらない。
out ならその引数変数に値を代入すると呼び出し元が変わり、
代入前はその型の変数の初期値になっている。inout なら、
値を入れると呼び出し元が代わり、初期値は呼び出し元の変数の値、といった感じ。
なお、inout を ref と改称しよう、という話もある模様。
2004/07/26追記。outの問題、D 0.96 でやっと修正されたそうな。
めでたし。
本題
クラスを書いてみます。
import stream;
class Dog
{
char[] name = 'pochi';
void bow()
{
stdout.writeLine( name ~ ': BowWow!' );
}
}
int main( char[][] arg )
{
Dog d = new Dog;
d.bow();
return 0;
}
>> 実行結果
pochi: BowWow!
そういえば、文字列の連結演算子 ~
が存在するそうです。
- classのインスタンスを指す変数は、全部リファレンス
- インスタンスの作成は、new で行う。
- フィールド(メンバ変数)の定義のところで、デフォルトの初期値、を書ける
- メンバ関数(メソッド)の定義も、必ずclass{}の中に書かねばならない
- class定義の最後に ; は要りません
- 特に何も書かないと、classのフィールド、メンバ関数は全てpublic
もちろん関数定義と同じく、上の例で main より下に class Dog ...
を持ってきても一向に構いません。この辺りは、文法的には
Javaに非常に近いですね。
プロパティ
まだ実装されていないとのこと。残念。
module (2003/01/18)
ちょっと話の都合上、class の話を一旦中断します。さて、module。
Dでは、1つのファイルが1つの「モジュール」になります。
例1
eq2d.d
import math;
double[] solve_2d_eq( double a, double b, double c )
{
double[2] x;
x[0] = (-b + sqrt(b*b - 4*a*c)) / (2*a);
x[1] = (-b - sqrt(b*b - 4*a*c)) / (2*a);
return x;
}
test.d
import c.stdio;
import eq2d;
int main( char[][] arg )
{
double[] x = solve_2d_eq( 1, 6, 5 );
printf( "%f %f\n", x[0], x[1] );
return 0;
}
>> コンパイル方法&実行結果
> dmd eq2d.d test.d
C:\usr\develop\DigitalMars\bin\link.exe eq2d+test,,,user32+kernel32/noi;
> eq2d
-1.000000 -5.000000
eq2d.d というファイルをコンパイルすると、eq2d という「モジュール」
になります。で、これを import すると、別のファイルからも
eq2d.d 内の関数、例えば solve_2d_eq が使えるようになります。
例2
eq2d.d
module equation_solver;
import math;
double[] solve_2d_eq( double a, double b, double c )
{
double[2] x;
x[0] = (-b + sqrt(b*b - 4*a*c)) / (2*a);
x[1] = (-b - sqrt(b*b - 4*a*c)) / (2*a);
return x;
}
1行目にご注目。ファイル名をそのままモジュール名として使うのではなく、
キーワード module によって、
明示的に自分のモジュールの名前を宣言することも可能です。この場合、
使う側は import equation_solver; と書くことになります。
またここで、module c.stdio のような、
階層化した名前をつけることもできるそうです。
メモ
equation_solver.solve_2d_eq( ... )
のような書き方はできない? 位置づけ的には、Javaのimportより、
C/C++の#includeや#importに近いのかも- namespace的なものは無いっぽい。
initialization
C++では、「グローバル変数の初期化順序は不定」という問題がありました。
Dの場合、「モジュール内では、上から順に初期化」「モジュール間では、
importする側よりされる側を先に初期化」という方針で初期化されるそうです。
それ以外の順序は、依存関係が存在しないはずなので、不定。
- なので、循環import(AがBをimport、BがAをimport)は、
双方がグローバルなオブジェクトを持つときは不正と見なされる
- グローバルなのがなければ問題なし
attributes (2003/01/18)
関数宣言やclassの宣言にて、「属性」を付加することができます。
さっきの例をいじってみましょう。
import math;
extern(C) double[] solve_2d_eq( double a, double b, double c )
{
double[2] x;
x[0] = (-b + sqrt(b*b - 4*a*c)) / (2*a);
x[1] = (-b - sqrt(b*b - 4*a*c)) / (2*a);
return x;
}
C言語のリンケージを持つ関数としてコンパイルされます。
extern(C) や extern(D)、
Win32環境であれば extern(Windows) などの属性がサポートされます。
属性を書く文法には3通りあって、
属性 宣言;
C++でinlineとか書くような、JavaやC#でprivateとか書くような位置。
一つの宣言にだけ有効です。
属性:
宣言;
C++でpublic:とか書くような位置。これ以降全ての宣言にその属性を付加します。
属性
{
宣言;
}
C++でextern "C" とか書くような位置。
ブロック内の全ての宣言にその属性を付加します。
どの属性も全ての方式を使って書けるようです。
属性色々
align
struct Aaa
{
align(8):
int x;
int y;
}
メンバを8バイト境界に配置するように指示。
deprecated
deprecated
{
void old_function() { ... }
}
非推奨の機能です他を使ってください属性。
export
実行ファイルの外からアクセスできる属性。例えばDLLからexportする、みたいな。
const
int main( char[][] arg )
{
const int x = 10;
x = 20; // error! test.d(5): '10' is not an lvalue
return 0;
}
変数ではなく、定数宣言に。コンパイル時に x は定数
10 と評価されることになります。
static
インスタンスフィールド/メソッドでなく、
クラスフィールド/メソッドである、という属性。
C/C++の、ファイルの内部関数である、という意味は持たない。
そういう目的には private を使うそうな。
auto
override
final
後述
private
protected
public
class や module のメンバにつけることのできる属性。
privateは自分自身からしかアクセスできなくて、protected
は自分かまたはその派生クラスからのみで、public はどっからでもOK、と。
ただ、α版のせいか private の挙動が怪しい気がする。
class の private メンバが module-private 扱いで、module-private
が無視されてるような。
constructor / destructor (2003/01/19)
クラスのインスタンスがnewで作成されるとき、
GCで破棄されるときにそれぞれ呼ばれる関数を定義できます。
この特殊な関数には、this と ~this
という名前を付けます。
import stream;
class Test
{
this()
{
stdout.writeLine('instance of Test created.');
}
~this()
{
stdout.writeLine('instance of Test destroyed.');
}
}
int main( char[][] arg )
{
Test t = new Test;
stdout.writeLine('lululu...');
return 0;
}
>> 実行結果
instance of Test created.
lululu...
instance of Test destroyed.
C++だとクラスと同じ名前の関数をコンストラクタとするわけですが、
おかげで無名クラスにはコンストラクタを作れない、という非常に残念な仕様でした。
これはその点の改善だろう!と考えたのですが、どうもDには無名クラスは存在しない模様。
となると他に嬉しい点としては、内部実装がクラス名に縛られないで済む、とか。
引数付き
import stream;
class Test2
{
int m_x = 1;
this(int x)
{
m_x = x;
}
this()
{
m_x = 3;
}
this(char[] s)
{
}
}
int main( char[][] arg )
{
Test2[3] t;
t[0] = new Test2;
t[1] = new Test2(100);
t[2] = new Test2('hello');
for( int i=0; i!=t.length; ++i )
stdout.writeLine( toString(t[i].m_x) );
return 0;
}
>> 実行結果
3
100
1
引数付きコンストラクタも、上のように書けます。
まずフィールド定義時に与えたデフォルト値(int m_x = 1;)があって、
コンストラクタでそれを上書きする、という形になっていることがわかります。
別のコンストラクタを呼ぶ
import stream;
class Test3
{
int m_x = 1;
this(int x)
{
this();
m_x = x;
}
this()
{
stdout.writeLine('initialized');
}
}
int main( char[][] arg )
{
Test3 t = new Test3( 100 );
return 0;
}
>> 実行結果
initialized
一般的な初期化処理をデフォルトコンストラクタに書いて、
ユーザーから特別にパラメータを与えられた時の処理を引数付きコンストラクタに書く、
というのは頻出の方法だと思います。コンストラクタから他のコンストラクタは呼べない、
というような言語だと、一般的な初期化処理を別の関数に分割するか、
同じコードを二箇所に書くか、しかありませんでした。
// 2回書く例
class Cpp {
int m_x;
Cpp(int x):m_x(x) { cout << "initialized" << endl; }
Cpp() :m_x(0) { cout << "initialized" << endl; }
};
// 初期化関数に分ける例
class Cpp {
int m_x;
void init() { cout << "initialized" << endl; }
Cpp(int x):m_x(x) { init(); }
Cpp() :m_x(0) { init(); }
};
私がC++に対して一番不満だったのがこの点なので、これは素晴らしい、
と思わず叫びそうになってしまいます。まぁ、
当たり前といえば当たり前に言語に備わっていて欲しい機能ではあるのですが。
super
継承の話はまだチェックしてないですが、親クラスのコンストラクタを呼ぶには、
super() だそうです。
Garbage Collection / auto (2003/01/20)
メモリ解放はGCで行われます。で、メモリ解放時に、GCがデストラクタを呼び出します。
import stream;
class Check
{
char[] m_s;
this(char[] s) { m_s = s; }
~this() { stdout.writeLine(m_s); }
}
int main( char[][] arg )
{
if( true )
{
Check t1 = new Check( 'a' );
}
Check t2 = new Check( 'b' );
Check t3 = new Check( 'c' );
Check t4 = new Check( 'd' );
return 0;
}
>> 実行結果
d
c
b
a
使われなくなった順とかではなく、偶然かそうでないかはわかりませんが、
作成されたのと逆順で破棄されています。
Resource Acquisition Is Initialization (RAII)
GCを使う場合、一般には「いつGCが走るかは保証されない」
という欠点があります。従ってGCのみの言語では、
使い終わったら一刻も早く解放する必要がある…例えば、
Mutexなどの資源の解放をデストラクタ/ファイナライザに任せることはできません。
人間が手でUnlock操作を書く必要がでてきてしまいます。
import stream;
class Check
{
char[] m_s;
this(char[] s) { m_s = s; }
~this() { stdout.writeLine(m_s); }
}
int main( char[][] arg )
{
if( true )
{
auto Check t1 = new Check( 'a' );
}
auto Check t2 = new Check( 'b' );
auto Check t3 = new Check( 'c' );
auto Check t4 = new Check( 'd' );
return 0;
}
>> 実行結果
a
d
c
b
変数宣言にキーワード auto をつけることによって、
スコープアウト時にデストラクタが必ず呼ばれるように保証できます。
つまり、RAII と呼ばれるプログラミング作法をサポートしています。
上のコンストラクタ周りがC++の最もダメな部分だとすれば、
このRAIIサポートはC++の最も素敵な部分だと私は思っているので、
Dにしっかり継承されているのは嬉しいところです。
しかもGC付きなので、安全性は確実に増しているでしょうし。
import stream;
auto class Check
{
char[] m_s;
this(char[] s) { m_s = s; }
~this() { stdout.writeLine(m_s); }
}
int main( char[][] arg )
{
auto Check t1 = new Check( 'a' );
Check t2 = new Check( 'b' );
return 0;
}
>> コンパイル結果
test.d(13): variable t2 reference to auto class must be auto
class宣言にauto属性をつけると、
autoでない変数を作ることを禁止するクラスになったり。
inheritance (2003/01/20)
継承です。
import stream;
class Dog
{
void bark() { stdout.writeLine('bow!'); }
}
class QuietDog : Dog
{
void bark() { stdout.writeLine('...'); }
}
class VeryOftenBarkingDog : Dog
{
void bark() { stdout.writeLine('bow!wow!bow!'); }
}
int main( char[][] arg )
{
Dog taro = new QuietDog;
Dog pochi = new VeryOftenBarkingDog;
taro.bark();
pochi.bark();
return 0;
}
>> 実行結果
...
bow!wow!bow!
タロー君の元気がないのが気になるサンプルですがそれはともかく、
継承は親クラスを : で指定。
- 全てのクラスは Object クラスの派生
- クラスの多重継承は無し
- private/protected継承は無いように見える
- 放っておくと全部のメンバ関数は多態に。C++でいうvirtual関数
- ドキュメントに記述が見あたらなかったのですが、final属性ををつけると、
期待通りそれ以上派生するの禁止なクラスとか関数とかになる。
interface
interface があります。この辺りはほぼ、Javaそのまんまですね。
import stream;
interface Animal
{
char[] how_you_cry();
}
class Dog : Animal { char[] how_you_cry() { return 'bark'; } }
class Cat : Animal { char[] how_you_cry() { return 'mew'; } }
class Horse : Animal{ char[] how_you_cry() { return 'neigh'; } }
class Cow : Animal { char[] how_you_cry() { return 'moo'; } }
class Mouse : Animal { char[] how_you_cry() { return 'squeak'; } }
int main( char[][] arg )
{
Animal[] a;
a ~= new Dog;
a ~= new Cat;
a ~= new Horse;
a ~= new Cow;
a ~= new Mouse;
for(int i=0; i!=a.length; ++i)
stdout.writeLine( a[i].how_you_cry() );
return 0;
}
>> 実行結果
bark
mew
neigh
moo
squeak
- interface は多重継承もOK。
- classとinterfaceを両方継承するときは、classを最初に書くことで区別。
override
あと便利そうなキーワードとして、override
というのが追加されています。
import stream;
class Dog
{
void bark() { stdout.writeLine('bow!'); }
}
class QuietDog : Dog
{
override void bark() { stdout.writeLine('...'); }
}
class VeryOftenBarkingDog : Dog
{
override void berk() { stdout.writeLine('bow!wow!bow!'); }
// おっと、綴りを間違えた!
}
int main( char[][] arg )
{
Dog taro = new QuietDog;
Dog pochi = new VeryOftenBarkingDog;
taro.bark();
pochi.bark();
return 0;
}
>> コンパイル結果
test.d(15): function berk function berk does not override any
「このメンバ関数は親クラス/インターフェイスのをoverrideしてるんだっ!」
と主張する属性がoverrideです。上の例だと、overrideが無い場合、
berkと綴りを間違えていてもコンパイルが通ってしまい class VeryOftenBarkingDog
のインスタンスに対し bark() すると、親の Dog で定義された bark()
が呼ばれてしまうことになります。
綴りミスでなくても、親クラス側で引数の変更や名前の変更があったりしたときなど、
override 指定しておくことで、
コンパイル時に不整合を確実に見つけることができるようになります。
休憩 (2003/01/20)
一度マトメてみる
C的な
- プログラムがグローバル関数 main() から始まるとか
- [Skipped] ポインタもあるみたい。
- [Skipped] enum,union,structもあるみたい。
Java / C# 的な
- Garbage Collectionによる管理
- 全てのクラスがObjectから派生
- classの多重継承は無し、interfaceはあり
- class変数は全部参照型
- final属性
- class/関数の定義順の自由性
C#的な
- [Skipped] structは値型
- [未実装] property
- override属性
C++的な
その他、細かな改善
( 無さそうなもの )
- namespace, package のようなもの
- 引数名の省略
さて
…というわけで、ここまでのところは、
他のC系統言語の用語一発で説明がつくような、言わば
「いいとこ取り」 な部分について長々と見てきました。
私にとっては final と delegete と auto が全部使える言語、
というのはそれだけで非常に魅力的です。が、まだまだ終わりません。
ここからは、この系統の他の言語と比べて、D の独自な部分、
あるいは他と共通の機能ではあるけれど、大きく姿を変えている部分、
について。
type (2003/01/22)
intとかcharとかfloatとか、普通なものは普通にあります。
基本型としてやや特徴的なのが、
import c.stdio;
int main( char[][] arg )
{
complex t = 1 + 2i;
complex s = -2 + 2i;
complex u = t * s;
printf( '%f %f', u.re, u.im );
return 0;
}
>> 実行結果
-2.000000 0.000000
複素数型。接尾辞i で虚数を表すことができます。
int main( char[][] arg )
{
bit x = 1;
bit y = 0;
bit z = cast(bit)((x^y) | (x&y));
return 0;
}
bit型。1か0をとります。最後のzの初期化で cast
が要るのが納得行かないんですけどまぁいいか。
あとは派生型として、ポインタ型、配列型、関数型があるそうです。詳細略。
typedef / alias
型の別名を定義するものとして、typedef があります。
typedef int resource_handle;
こう書くと、resource_handle というのが、
中身はintと同じ別の型として扱えるようになります。
別の型というのがポイントで、C/C++のtypedefと違い、
本当に別の型として扱われます。つまり例えば、
typedef int resource_handle;
void f( int x ) { ... }
void f( resource_handle x ) { ... }
というコードはC++では「同じ名前で引数の型も個数も全く同じ関数が二つあります」
とエラーになりましたが、Dでは無事コンパイルできます。(C/C+流の typedef
の用途には、alias という別のキーワードを使います)
しかし実際は「全く同じ」なので上の二つの関数は、
そのままでは曖昧になってしまいます。そこで暗黙の型変換に制限があります。
上の例でいうと、resource_handle から int への暗黙の変換は可能で、
int から resource_hanlde へは明示的に変換しないとダメとのこと。
import c.stdio;
typedef int height;
typedef int weight;
void f( char[] name, height h, weight w )
{
printf( "%.*s: 身長=%d cm 体重=%d kg\n", name, h, w );
}
int main( char[][] arg )
{
f( "taro", cast(height) 178, cast(weight)60 );
f( "hanako", cast(height) 160, cast(weight)47 );
return 0;
}
>> 実行結果
taro: 身長=178 cm 体重=60 kg
hanako: 身長=160 cm 体重=47 kg
この関数はheightとweightのどっちを先に渡すんだっけ?
みたいなことが減って良い感じ、ということだと思います。
メモ
alias は型の別名だけでなく関数の別名とかにも使えるらしい。
alias math.sin sin;
delegate
C#などにあるdelegateを備えてます。オブジェクトとメンバ関数をひとまとめにして、
後で関数っぽく呼べるもの、とでもいいましょうか。
import stream;
class Abc
{
char[] s;
void print() { stdout.writeLine(s); }
}
int main( char[][] arg )
{
Abc a = new Abc;
void delegate() ev = &a.print;
a.s = 'aiueo';
ev();
return 0;
}
>> 実行結果
aiueo
operator overload (2003/01/23)
+ - * / や ==, < >= など、演算子の挙動を、
演算される値の型によってユーザー定義で切り替えることができます。
import stream;
class Point
{
int x, y;
this(int ix,int iy) { x=ix, y=iy; }
int eq(Point rhs) { return x==rhs.x && y==rhs.y; }
// x座標優先で順序関係をつける
int cmp(Point rhs) {
if(x < rhs.x) return -1;
if(x == rhs.x)
if(y < rhs.y) return -1;
else if(y == rhs.y) return 0;
return 1;
}
}
int main( char[][] arg )
{
Point p = new Point(1,2);
Point q = new Point(2,1);
Point r = new Point(1,2);
if( p < q )
stdout.writeLine( 'p < q' );
if( p == q )
stdout.writeLine( 'p == q' );
if( p == r )
stdout.writeLine( 'p == r' );
if( p === r )
stdout.writeLine( 'p === r' );
return 0;
}
>> 実行結果
p < q
p == r
等しいなら0以外、等しくないなら0を返す eq、というメンバ関数が定義されていると、
== と != という演算子を書いたときに、eq()
が呼ばれるようになります。p == q が p.eq(q)
と同じ意味になるわけです。同様に、< > <= >= に対しては
負,0,正 の数を返す cmp で。他の色々な演算子に関しても、対応する
関数
を定義することで、ユーザー定義することができます。
operator < (const Point& rhs)
とかダイレクトに定義する C++ より抽象性が増していて良い感じですが、
反面boost::lambdaのようなヘンなことはできなくなっています。
できなくてよいような気もしますが。
template (2003/01/26)
対象とする型を特定しないでアルゴリズムやデータ構造を書くことで、
一つのソースでどんな型に対しても適用できる関数/クラスを書く…
という手法、を実現します。
import c.stdio;
template arith_functions(T)
{
T add(T a, T b) { return a+b; }
T sub(T a, T b) { return a-b; }
T mul(T a, T b) { return a*b; }
T div(T a, T b) { return a/b; }
}
int main( char[][] arg )
{
instance arith_functions(int) ar_int;
instance arith_functions(double) ar_dbl;
printf( "%d\n", ar_int.add(100, 200) );
printf( "%d\n", ar_int.sub(100, 200) );
printf( "%f\n", ar_dbl.mul(100, 200) );
printf( "%f\n", ar_dbl.div(100, 200) );
return 0;
}
>> 実行結果
300
-100
20000.000000
0.500000
template hogehoge(T) { ... } で囲むことで、その中では
genericな型 T についての関数定義やクラス定義を行えるようになります。
定義した関数などを実際に特定の型(例えばint)に特化して使うには、
instance というキーワードによって、実体化します。
C++のtemplateとの比較
C++のtemplateは関数、またはクラス毎に指定するものでしたが、D の場合、
いわばC++のnamespace単位でテンプレート化する、と言って良いと思います。
上の例を疑似C++で書き直すと、次のような感じ。
#include "stdio.h"
template<typename T> namespace arith_functions
// ここら辺正しいC++ではないので注意
{
T add(T a, T b) { return a+b; }
T sub(T a, T b) { return a-b; }
T mul(T a, T b) { return a*b; }
T div(T a, T b) { return a/b; }
}
int main( const char* arg[] )
{
namespace ar_int = arith_functions<int>;
namespace ar_dbl = arith_functions<double>;
printf( "%d\n", ar_int::add(100, 200) );
printf( "%d\n", ar_int::sub(100, 200) );
printf( "%f\n", ar_dbl::mul(100, 200) );
printf( "%f\n", ar_dbl::div(100, 200) );
return 0;
}
直接的には無いとはいえ、DではC++の「クラステンプレート」
と同じものは簡単に書けます。用はクラス定義の外をtemplateで囲めばOK。
ついでにそのクラスに関するフリー関数も同じtemplateスコープに入れれば、
わかりやすくなってよい感じです。
template vector(T)
{
class t
{
private T[] data;
public T at(int i) {...};
...
}
}
...
instance vector(int).t x = new ...; // 変数宣言
x.pushback(1);
int c = x.get(0);
...
が、関数テンプレートが書けないのがちょと困りもの。
いや、同様に関数テンプレートも書けるのですが、型演繹が使えないのが。
// D
template max(T)
{
T f(T a, T b) { return a < b ? a : b; }
}
instance max(int) intmax; // 対象がintであることを明示的に指定
int c = intmax.f(1,2);
// C++
template<typename T> max(T a, T b)
{
return a < b ? a : b;
}
int c = max(1,2); // 引数の型からコンパイラが推論
これは結構使いにくい気がするので、おそらく、
この手の使い方は今のところは重視されていないのではないかな、
と推測しています。今後の計画として、各種コンテナ用に foreach
構文を用意してループをそれで回そう、という方向があるらしいので、
genericなアルゴリズムはtemplateでない別の方法で記述しようと言うことでしょうか。
やや残念。
文法面では、閉じ括弧>>がシフトに見なされるとか、
場合によってはメソッド名の前に template
キーワードが無いと困るとか、そういう破綻寸前の話が起こらないように、
整理されていますね。関数宣言と同じに 名前( パラメタ )
の形で宣言できるのは個人的には好み。
Specialization
template abc(T) { ... } // 一般の場合
template abc(T : int) { ... } // intの場合の特別バージョン
template abc(T : T[]) { ... } // 何かの配列だった場合の特別バージョン
template abc(T,U,V) { ... } // 型パラメータが3つだった場合の一般版
特定の型の時に別の実装にしたいときは、上のように :
の後ろに書くことで特別バージョンを定義できます。
explicit/partial の双方の specialization 可能。
# ということはそれなりにはtemplate-meta programming可能?
Digital Mars D 0.51 alpha (2003/01/27)
Dコンパイラの新バージョンが出ました。
ダウンロードはいつもの通りこちらから。変更点としては、
- templateへ、型だけでなく値パラメータも渡せるようになった
- templateに関する問題を幾つか修正
- pragma #line のサポート。行番号やファイル名の情報を、
ソースコード中のほぼ任意の位置に挟み込むことができます。
これはトランスレータやコンパイラを書く人向け(空白,改行文字を潰した後でも、
わかりやすいエラーメッセージを出力することが簡単になる)の機能なので、
とりあえず一般ユーザはあまり関係ないかと思います。
- Unicodeのソースファイルのサポート。
UTF-8/UTF-8N/UTF-16(LE/BE双方。BOM付き)/UTF-32(LE/BE双方。BOM付き)
で書けるそうです。ただし、まだ文字列リテラル "hogehoge"
の中は正しく扱えない模様。
とな。outパラメータの件はまだみたい。
templateの値パラメータ
template Abc(int Initval)
{
class Def
{
int value = Initval;
}
}
instance Abc(100) Abc100;
Def ghi = new Abc100.Def;
...
などと、templateに整数値を渡せるようにする機構だと思われます。が、
現在の所、「non-constant expression Initval」と怒られてしまって、
上手く使えません。ドキュメントのサンプルもコンパイル通らない…。
どなたか詳細ご存じの方いらしましたら、情報いただけると嬉しいです。
intの代わりにchar[]としたテンプレートを定義しようとすると
「template foo(char[]) integral type expected for value-parameter, not char[]」
と怒られてしまうので、整数値以外は使えないっぽいですね。
exception (2003/01/31)
例外処理。try{} でくくった中で例外的な事象が発生すると、外の catch
ブロックに処理が移ります。で、例外発生の有無にかかわらず、try
ブロックが終了すると、必ずfinallyブロックが実行されます。
import stream;
class A { int a; }
int main( char[][] arg )
{
try
{
A a; // newで作ったオブジェクトを指していない変数なので
a.a = 10; // アクセスしてはいけないはず
}
catch( Exception e )
{
stdout.writeLine( 'exception... ' ~ e.toString() );
}
finally
{
stdout.writeLine( 'end of program' );
}
return 0;
}
>> 実行結果
exception... Access Violation
end of program
自分で例外を起こしたいときは、throw hogehoge とやって、
例外オブジェクトを投げることになります。まぁ、ごく普通。
properties for primitive objects (2003/02/01)
組込型オブジェクトにも、幾つかプロパティがあります。
import c.stdio;
int main()
{
int a = 0;
int b = 1;
int c = 2;
printf( "%d %d %d %d\n", a.init, b.init, c.init, int.init );
printf( "%d %d %d %d\n", int.max, int.min, int.size, short.max );
return 0;
}
>> 実行結果
0 1 2 0
2147483647 -2147483648 4 32767
maxとかminとかはその型で表せる最大/最小値、ですね。sizeはC/C++でいうsizeof。
その型が何バイトのメモリを消費するかが得られます。
変わっているのが init。変数名.init とした場合、その変数を初期化したときの
初期化値が得られます。何に使うんだろう。
配列の処理
- D では、文字列 == charの配列 である
- C/C++は言語レベルでの文字列サポートがなっとらんので改善したい、
とWalter氏は考えたらしい
という二つの前提から導かれる結論として、何だか組み込みの配列が、
結構多機能になっています。スクリプト言語の配列っぽい勢いです。
具体的には、次のような感じ。
- 動的に長さを変えることができる
- subarrayの取り出し
- 複数の要素に同じ演算をする記法が存在
- 連想配列
C++ の std::valarray に近いかな。
import c.stdio;
int main()
{
int[] x;
// 配列サイズを実行時に指定
x.length = 10;
for(int i=0; i!=x.length; ++i)
x[i] = i;
// x[1], x[2], x[3] に10を代入
x[1..4] = 10;
for(int i=0; i!=x.length; ++i)
printf("%d ", x[i]);
printf("\n");
// xを複製してyへ。で、それを逆転して、xに追加
int[] y = x.dup;
x ~= y.reverse;
for(int i=0; i!=x.length; ++i)
printf("%d ", x[i]);
printf("\n");
// xを並び替え
x.sort;
for(int i=0; i!=x.length; ++i)
printf("%d ", x[i]);
printf("\n");
return 0;
}
>> 実行結果
0 10 10 10 4 5 6 7 8 9
0 10 10 10 4 5 6 7 8 9 9 8 7 6 5 4 10 10 10 0
0 0 4 4 5 5 6 6 7 7 8 8 9 9 10 10 10 10 10 10
他に
// xの真ん中辺りだけ並び替え
x[5..15].sort;
// 適当に取り出して複製
int y[] = x[2..10].dup;
なども当然可能です。ドキュメントを読む限りでは更に
// xの一部に20を足したものをyの一部に代入
y[3..6] = x[10..13] + 20;
もできるように読めるのですが、コンパイルエラーになってしまいました。
配列のindexとして、数値以外に文字列もとったりできます。
import c.stdio;
int main()
{
int[char[]] s;
s["hello"] = 10;
s["good morning"] = 20;
s["good evening"] = 30;
s["good night"] = 40;
if( s["good night"] - s["hello"] == s["good evening"] )
printf("%d\n", s["good morning"]);
return 0;
}
>> 実行結果
20
debug / version (2003/02/02)
デバッグ版やプラットフォーム依存コードは、C/C++では、
プリプロセッサの#ifdefを使って切り分けるものでした。
D では、debug という構文と、version という構文が用意されています。
import c.stdio;
import math;
double solve2d_eq(double a, double b, double c)
{
// デバッグレベル2なら、関数呼び出しを表示
debug(2) { printf("begin solve2d_eq\n"); }
// デバッグレベル3なら、その引数も表示
debug(3) { printf(" | %f %f %f\n",a,b,c); }
double d = b*b - 4*a*c;
// デバッグレベル1なら、虚数解の検証
debug(1) {
assert( d >= 0 );
}
return (-b + sqrt(d)) / (2*a);
}
int main()
{
solve2d_eq( 1, 1, 1 );
return 0;
}
>> 実行結果
> dmd test.d
> test
> dmd -debug=1 test.d
> test
Error: Assertion Failure test.d(11)
> dmd -debug=2 test.d
> test
begin solve2d_eq
Error: Assertion Failure test.d(11)
> dmd -debug=3 test.d
> test
begin solve2d_eq
| 1.000000 1.000000 1.000000
Error: Assertion Failure test.d(11)
debugレベルの指定には、数値だけではなく、意味のある識別子を使うこともできます。
versionの方でも全く同様ですので、versionの例で見てみましょう。
int main()
{
do_opening_movie();
version(Demo)
{
return; // デモ版はここでおしまいです
}
game_begin();
return 0;
}
> dmd -version=Demo main.d
...
処理系や、OS、プロセッサの環境を示すversion識別子が幾つか予め定義されています。
一例として、LittleEndian。
void save_uint( uint n )
{
// リトルエンディアン版ならByteOrderを変換してから保存
version(LittleEndian)
{
n = (n>>24) | (n<<8>>24<<8) | (n<<16>>24<<16) | (n<<24);
}
save_uint_impl( n );
}
version/debug には対応する else が付けられる模様。
import宣言と、const,align,version,debug などの属性、
によってCのプリプロセッサの普通の使い方は全てカバーできるだろう、
ということで、C/C++の様なプリプロセッサはDには存在しないとのこと。
Javaではgcc -Eの助けを借りたりすることが希にありましたけど、
確かに debug{} があれば十分かもしれません。
contract / invariant / unittest (2003/02/02)
D言語の制作者である Walter Bright 氏はC/C++コンパイラにも拡張として
Design By Contract をサポートする機能を追加している方なので、
独自の言語である D にももちろん備わっています。
D言語のDはDBCのDではないかと考えてしまったりする今日この頃。さて。
import math;
// int square_root( int x )
// {
// return math.sqrt(x);
// }
int square_root( int x )
in
{
assert( x>=0 );
}
out( result )
{
assert( result*result == x );
}
body
{
return math.sqrt(x);
}
平方数(何か別の数を2乗した数)であることがわかっている整数の、
平方根を求めることを考えます。まずこの関数の 入力は0以上
でなければ意味が無く、正しく計算されたなら、出力の2乗が入力と等しい
はずです。これをそのままコードに落とすと、上のようになります。
で、実際この関数を不正な引数で呼び出すと、assert文で例外が発生します。
型情報以上に強い入出力条件を書くには、C/C++だと 「仕様」
としてコメントに書いておくくらいなものですが、それだと、
違反してもすぐにはわかりません。が、上のようにチェックコードが書けて、
実際にチェックが実行されるとなると、バグの検出が早くなることが期待できます。
それに、コメントで書く(…入力は0以上…)よりもコードで書いた(…x>=0…)
方が曖昧性が減って、良さそうです。
無論 assert を使えばC/C++でも条件チェックは相当程度書けるわけですが、
out にあたるチェックを言語サポート無しで書くには、
body を変更せずに行うのは難しいでしょう。
class invariant
上の in~out では関数の入力と出力に関する条件、つまりいわゆる
「事前条件」と「事後条件」の記述ができました。さらに、
クラス毎に「不変条件」を書くことができます。
class Rect
{
int width=0, height=0;
void SetWidth(int w) { width = w; }
void SetHeight(int h) { height = h; }
invariant
{
assert( width >= 0 );
assert( height >= 0 );
}
}
class Square : Rect
{
void SetWidth(int w) { width=height=w; }
void SetHeight(int h) { width=height=h; }
invariant
{
assert( width == height );
}
}
int main()
{
Rect r = new Rect;
r.SetWidth(-10);
return 0;
}
>> 実行結果
Error: Assertion Failure test.d(8)
このクラスが正しい状態にある限り常に変わらず成り立っていなければならない条件、
をinvariantの中に書いておくことで、コンストラクタの直後、及び public
メソッドの呼び出し前後にチェックが行われるようになります。
上の例だと、「長方形は、幅と高さは負であってはならない」と
「正方形は、幅と高さが等しい」といった条件をinvariantに記述しています。
余談ですが上のような Square : Rect という派生関係は、間違った継承の使い方の
代表例 らしいのでよい子の皆さんは真似しないように。^^;
unittest
プログラム上の部品一つ一つについて、予定した通りにちゃんと動くか、
のテストを「単体テスト」と呼びます。各Unit、各機能毎にテストコードを
書いておいて、それを何度も何度も実行してチェックしつつ開発を進めることで、
早期にバグが発見できて嬉しいな、という話なわけですが。
この各ユニット毎のテストを全部集めてきて実行して成功/失敗の情報を集めて…
っていうのは何も人間がやる必要はないので、
Java用のJUnit、C++用の
CppUnit、Ruby用の
RubyUnit…
などなど、テスト用フレームワークが各言語向けに開発され、広く利用されています。
で、そのUnitTest用の簡単なフレームワークを、Dは言語レベルで備えているそうです。
// 引き算クラス
class Dif
{
int sub(int x,int y)
{
// おっと、x-yのつもりが、間違えてx- -yになっている!
return x - -y;
}
unittest
{
Dif x = new Dif;
assert( x.sub(4,3) == 1 ); // このメソッドは引算として働くべき
}
}
int main()
{
return 0;
}
> dmd -unitest test.d
> test
Error: Assertion Failure test(13)
unittestオプションを付けてコンパイルすると、実行時に、
各クラスに最高で1個存在するunittestブロックを実行してくれます。
完全なUnitTestにはまだ力不足かなぁ、という気がしますが、
にしても、他のソフトを入れずにコンパイラだけでテストができるのは嬉しいところ。
release
と、ここまで2日に渡って色々デバッグやテスト向けの特徴を紹介してきましたが、
これらの実行の本筋とは別のコードは -release
オプションを付けてコンパイルすることで、無視されるようになります。
最終的な完成品は -release で作ることで、速度低下を避けることができます。
phobos (2003/02/03)
デジタル火星の言語の周りを回る標準ライブラリは、
その名も Phobos、火星の惑星衛星です。標準でどんなものが用意されているか、
見てみましょう。
わりと普通なもの
- conv (文字列to整数変換)
- ctype (文字種。isalphaとか)
- date (日時処理)
- file (ファイルの属性取得とか名前変更とか)
- math (数学関係)
- path (ファイル名処理。getExtとか)
- random (乱数)
- stdint (整数型のalias)
- string (文字列(char[])処理)
およ?と感じたもの
- outbuffer (データを配列に書き出し?ちょい謎)
言語中枢的なもの
- compiler (コンパイラ名とか、そういった情報)
- gc (GarbageCollector制御)
- object (全クラスの派生元であるObjectクラスの定義)
注目
- thread (スレッド処理)
- regexp (正規表現)
- stream (ファイルや標準入出力の処理)
- zip (zip書庫操作。未実装?)
)
そんなに、何ぃ?と驚くようなライブラリはありませんでした。
streamやthreadなどはクラスとして実装されています。
上の方の、ほとんどCと同じようなものは関数で実装されています。
気になるのが、標準にネットワーク通信というか、
ソケットライブラリがなさそうな点。これはstreamクラスを拡張して
すぐに何とでもできそうなのですが、このまま socket
無しだと少し残念だなぁ、という気はします。streamライブラリの作者の方が
D Sockets library (ページ下部)
もWindows限定ながら作成されたそうなので、期待はもてるか。
Threadを使ってみる
import stream;
import thread;
int thread_A(void* p)
{
for(int i=0;i!=100000;++i)
stdout.printf("A");
return 0;
}
int thread_B(void* p)
{
for(int i=0;i!=100000;++i)
stdout.printf("B");
return 0;
}
int main()
{
Thread tA = new Thread(&thread_A,null);
Thread tB = new Thread(&thread_B,null);
tA.start();
tB.start();
tA.wait();
tB.wait();
return 0;
}
>> 実行結果
AAAAAAABBBBAAAAAAABBBBBBBBAAAAAA.....
とまぁ、こんな感じ。上のように関数ポインタを渡す方式でなくて、
Threadから派生してrunをオーバーライドする方式も使えるらしい。
今のところ本当にThreadしかなくて、MutexとかSemaphoreとかの、
共有リソース制御はOSを直接叩くしかなさそう。
(2003/08/09追記) ロック処理は、予約語 synchronized を使う、
ということみたいですね。
other libraries (2003/02/04)
windows
Windows環境であれば、Windows API を直接いじることができます。
import windows;
int main()
{
MessageBoxA(null,"hello!","message_box",MB_OK);
return 0;
}
現状、MessageBoxA と書かねばならない辺りが直接過ぎですが。
versionを使って、次のように書いておけば、MessageBox、
で適切な方を呼べるようになります。これらのaliasはいずれ
windows モジュール自体でサポートされるのではないかなあ、と予想しています。
version(Unicode)
{
alias MessageBoxW MessageBox;
}
else
{
alias MessageBoxA MessageBox;
}
他に注意点を一つ。Dの文字列(= char[])は一般に、\0-terminate されていません。
従って、CのAPIに渡すときは、普通は直前に.append(0)して、
文字列に終端記号を付加する必要があるそうです。
文字列リテラルに限っては大丈夫とのことですが。
また、上のmain()で始まるソースだと、
起動時にコンソールウインドウが出現してしまいます。
というわけで、真面目にWindowsアプリを作るなら、C/C++と同様、
WinMainから書くことになります。あと、実行モジュールの定義ファイルが必要。
上の例をきちんと書き直すと、次のようになります。
test.d
import windows;
extern (C) void gc_init();
extern (C) void gc_term();
extern (C) void _minit();
extern (C) void _moduleCtor();
extern (C) void _moduleUnitTests();
extern (Windows)
int WinMain(HINSTANCE hi, HINSTANCE hp, LPSTR cmd, int sw)
{
gc_init();
_minit();
try
{
_moduleCtor();
_moduleUnitTests();
MessageBoxA(null,"hello!","message_box",MB_OK);
}
catch(Object e){}
gc_term();
return 0;
}
test.def
EXETYPE NT
SUBSYSTEM WINDOWS
コンパイル
> dmd test.d test.def
という感じで、WinAPIを使えるわけでした。
dig - A GUI Library for D -
OS非依存…を目標としている…GUIライブラリです。現在のところ、
Windows上でのみ動きます。
インストール方法
digのページ
からダウンロード&解凍。
もしDコンパイラがc:\dmd以下にインストールされていれば、
配布ファイルの中のgo.batを実行すればインストール完了です。
別の場所にインストールされていた場合、digc\digc.d 内の文字列とgo.batを、
全て適切なパスに書き換えてからgo.batを実行します。
使ってみる
import dig;
class MyMainWnd : Frame
{
Canvas canvas;
this()
{
super();
caption("test");
onLButtonDown.add( &mouseDown );
with( canvas = new Canvas(this) )
{
width(128);
height(128);
onPaint.add( &paintMainWnd );
grid(0, 0);
}
gridfit();
}
void mouseDown( Event e )
{
caption("left click");
}
void paintMainWnd( Event e )
{
canvas.beginPaint();
canvas.textColor(100,200,100);
canvas.textPrint(50,50,"hello!");
canvas.endPaint();
}
}
int main()
{
MyMainWnd w = new MyMainWnd;
w.showModal();
return 0;
}
これを、dmd ではなく、先ほどインストールされたはずの digc
というコンパイラでコンパイルします。(たぶんパスを適切に通すだけで、
dmdでもコンパイルはできると思いますが。)
実行結果
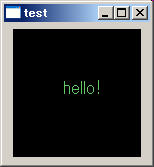
SDL import module for D
DedicateD で、
マルチメディアライブラリとして名高いSDLのD言語用モジュールが公開されています。
D用と言っても、DからはCの関数を呼べるので、基本的に C
で使うのとほとんど変わりません。そんなことを言っておきながら私は SDL
を使うのこれが初めてだったりするので、
本当に変わらないのかどうか自信はありません。が、
C向けの解説ページ
を見ながらDで書けたので、たぶん大丈夫でしょう。^^;
import SDL;
int main()
{
if( SDL_Init(SDL_INIT_VIDEO) < 0 )
return;
SDL_Surface* screen;
SDL_Surface* image;
try
{
screen = SDL_SetVideoMode(128,128,16,SDL_SWSURFACE);
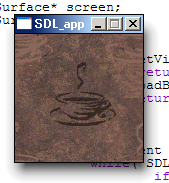
if( !screen ) return;
image = SDL_LoadBMP("coffee.bmp");
if( !image ) return;
while(true)
{
SDL_Event event;
while( SDL_PollEvent(&event) )
if( event.type==SDL_QUIT )
return;
static SDL_Rect dest = {x:0, y:0};
SDL_BlitSurface(image, null, screen, &dest);
SDL_UpdateRect(screen,0,0,image.w,image.h);
}
}
finally
{
if(image)
SDL_FreeSurface(image);
SDL_Quit();
}
return 0;
}
実行結果
その他のライブラリ
上記の DedicateD
をはじめ、DigitalMarsのリンクページからたどれるサイトでDの様々なソースが公開されています。
今のところGUIライブラリが多いみたい。
まとめ (2003/02/05)
感想としては、言語仕様がデカいなぁ、と。C++とJavaとC#が全部入って
+α されてるような感じを受けました。個々のテーマは後発なだけあって
色々と整理されていますが、「言語としてできること」の数が凄い。
途中でも書きましたが、私にとっては final と delegete と auto と real typedef
が使えてGCのあるC++、として見るだけでも非常に魅力的なので、
[話の種として面白い]だけでなく、実際に実用的なアプリを書く言語として
「使える」と思います。
あと特筆すべきはコンパイルの速さでしょうか。50KBのソースを、
Enterキーを離すより早くビルド終了するのには感心しました。
逆に、やや不安なのがライブラリの弱さ。これは今後のD言語コミュニティ次第、
と言ったところでしょうかね。もう少しtemplate関係をいじってみてから、
何か書けそうであれば私も書いてみようかなぁ、と思っています。
…というわけで、80KBを越えてしまったこのページもこれでお終いです。
ではでは~。
presented by k.inaba
under NYSDL.